To know what sources to trust, we rely on institutions in a similar way as we do for information itself. However, just like institutions are failing us with information, they are also failing us about what sources to trust. This is why a canonical model of trustworthy information sources created by an organization like Facebook, Google, or the government would not be trusted by a large number of people. Therefore, to reliably create and share source trust data, we need to work with people that we still trust, such as our friends or family. To share trust data with these close connections, my approach is to model the information sources–including our personal connections–and their relationships computationally.
To computationally model these information sources, relational formalisms like social networks, concept maps, and semantic web languages provide some inspiration in that they explicitly enumerate all the ways that entities are related to each other. Information sources can thus be modeled as having made information claims, as having authors, as being a news agency or a social media poster, and as being trusted or mistrusted by various people, all in the same model. Then these properties and relationships can be used to evaluate the trustworthiness of the sources — e..g, making “is trusted by my friend” one metric of a source’s trustworthiness.
With this additional “meta-information,” the trustworthiness of information sources can be estimated when you see a news article or social media post, and this estimate can be visualized. Visualizing meta-information can be done with color, size, or opacity — e.g., maybe a source is more trustworthy if it is more opaque, or maybe it is less trustworthy if it is outlined in red instead of green. Along with these basic visualizations, the details on how those visualizations were generated could also be exposed to users who are interested, such as which connections of yours labeled it as trustworthy. This method of exposing the evaluation’s rationale (also known as “explaining” itself) is called progressive disclosure. To combine these ideas, I will create an Ontology-Driven Source Evaluator.
To consistently evaluate the truth of claims, two separate steps are required: 1. enumerate the claims a source is making in an article, post, or other communication, and then 2. evaluate the truth value of these claims.
To enumerate the claims a source is making, it would be tempting to automatically scrape the content of a news article or social media post from the web page it’s on. However, this is not a great idea, at least initially, for a few reasons. First, lazy loading of content with scripting makes it difficult for an algorithm to know when to parse content. Second, document structures change over time, so successful scraping of content at one point in time will eventually break when the document structure changes. Finally, there are inconsistent document structures across sources, which means that the scraping code will have to be specialized for every information source.
It would also be tempting to use natural language processing (NLP) to extract the claims from a news article or social media post, but this is problematic as well. First, it’s very difficult since claims are written in different dialects, with slang, and so on. Second, it’s computationally expensive when evaluated against a language model to extract sentences, phrases, and claims. Finally, it’s untrustworthy when done with something like a deep neural network because its evaluation of a claim is completely opaque to the user.
A better approach, especially to start out with, is to enable the user to label text in a news article or social media post as a claim. This is rather manual, so it can be later supplemented with source-specific scraping templates for high-popularity sources (e.g., the New York Times or Twitter.com) and NLP suggestions of what might be a claim in a body of text. Then these algorithms can be further improved by teaching with previous manual labels about what words or phrases (n-grams) might indicate a claim statement.
To evaluate the truth value of these claims, user labeling is a tempting approach given its use to identify claims mentioned above. However, while users can be trusted to identify language that indicates a claim, they cannot be expected to reliably evaluate the claims for their truth value because they likely do not have the knowledge to make this judgment, and they very likely have their own biases about what is true and what isn’t. Therefore, it would be better to corroborate a claim made by a source with other trusted sources (including news articles, social media posts, and our personal connections). If they agree on the claim, then it is likely true. Also, the claim can still be manually labeled when a user has additional external knowledge on the subject matter. The resulting component will be the User-Centered Claim Evaluator.
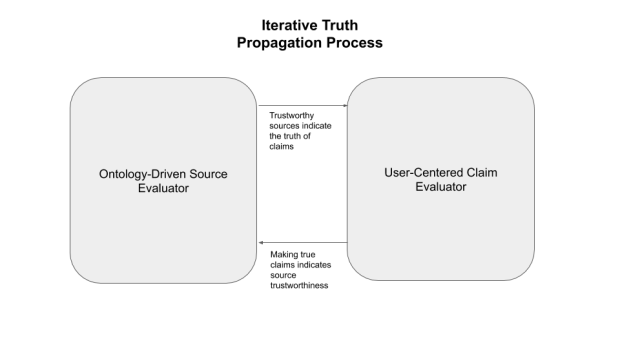
To use true claims to improve source trust data, an iterative process needs to be used because neither the truth of claims nor the trustworthiness of information sources can be entirely determined by themselves. Once you label a claim as true, your connections will see a claim populated with your trust label before it is evaluated against their source trust model. For your and your connections’ source trust models, the trustworthiness of a source can be incrementally increased as it makes more true claims. Over time, this Iterative Truth Propagation Process would converge into a distributed knowledge graph. Eventually, such a process could also generate new insights by synthesizing claims from one’s record of true claims.
Because this process is a recursive loop, it needs to start out with some data for both source trustworthiness and claim truth. Therefore, I will create initial models based on my own knowledge and research. Eventually, additional “experts” can restart this process with their own initial models.
I am working on addressing this problem right now. For more information, feel free to email me at bob@datagotchi.net.

One comment