Problem Space
To hire, test out product features, and grow, startups need money before they start making profits—they need investment. Investors want to have confidence that a startup they invest in will be able to grow enough so that they get a return on their investment. As a result, a concept was established called product-market fit, which is when a startup’s product is useful to one or more customer market segments and competes effectively with other products in that space.
However, most startups are not able to achieve product-market fit. There are several reasons for this, but a key aspect of it is that their product does not does not serve the needs of any potential customers. In other words, their product does not solve an actual problem. A term to describe this problem is not having problem-solution fit. This is a bit misleading for products that offer novel interactions rather than solving a problem, but it could be said that not being able to interact with people as much, or as effectively, is the problem such products are solving.
Therefore, startups must reach problem-solution fit. Then, after identifying some potential users that the product solves a problem of theirs, a startup should find a subset of them or their managers that are willing to pay for it (customers). This is the first step toward achieving product-market fit. In other words, to achieve product-market fit, a startup must first identify customers that are willing to pay for their product.
Finally, after achieving product-market fit, a startup must grow so that they can acquire enough dominance in the market space to attract acquiring companies or file an initial offering to become a publicly-traded company (i.e., an initial public offering, or “to IPO”).
Technical Requirements
To reach problem-solution fit, or to make sure you build something that people actually want or need, many startups think of something that they would want or need, or use their gut instinct. However, such approaches, while a good start, are prone to error. At the very least, startups should test their solution’s core value proposition–the benefit that it provides to users and customers. This can be done with signup forms on landing pages or created content. Then, possibly using the potential users and customers from these tests, some iterative user or customer research is necessary to continuously confirm that they have a problem that your product solves, and that a large enough number of them have this problem for similar reasons.
To reach product-market fit, or to make sure your product is useful to one or more customer market segments and competes effectively with other products in that space, a startup must start by determining who are users and who are customers. They may be the same people, the customers may be managers of users of your product, or the customers may be organizations running ads to the users. Then a startup needs to understand users’ and customers’ needs to understand what product space they’re in and how to compete in it. Again, while subjective
views and gut instincts are a start, something more formal is needed to identify go-to-market opportunities and verify they would serve a large number of people or organizations. The tests ran to reach problem-solution fit are also helpful because they may contain information about users’ and customers’ needs, or because they may provide a list of people for user or customer research.
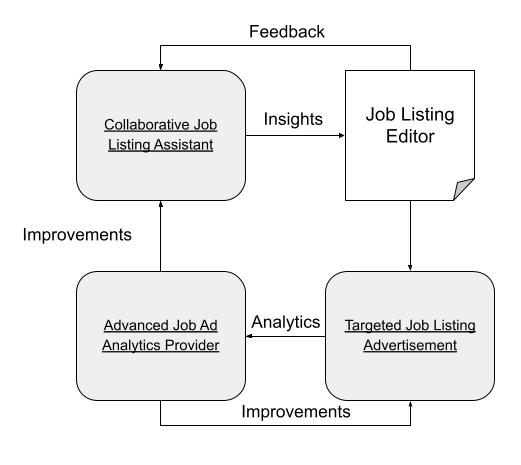
Finally, to grow, or to acquire enough dominance in the market space, a startup must optimize their successes delivering their product to users and customers and their success using it. Therefore, it is necessary for a startup to identify one or more channels to reach users or customers and deliver their product to them. Once the channels are identified, marketing funnels should be created for each of them, with potential users or customers and leads at the beginning, and prospects in the middle, and successful users or customers at the end. To increase the success between these funnel stages, a startup must iterate on their product and user or customer research to confirm their needs and success using it.
My Solution
The concepts of user experience (UX), human-computer interaction (HCI), and usability testing all have foundations from when a group of researchers in 1982 came up with the concept of cognitive systems engineering (CSE) in response to the Three Mile Island nuclear disaster of 1979. It was then formalized by a couple of those researchers in 1983 with the lens of people and machines working together as a joint cognitive system (JCS). With this lens, CSE became an approach to systems engineering to continuously verify one’s understanding of users and machines, their joint success or failures in operation, and how those failures can be addressed. A similar cyclical approach called human-systems integration (HSI) was also invented in the military to model each systems engineering iteration’s decisions as risk management. I have worked with both the researchers that invented these approaches, and their followers, in my past government R&D research scientist jobs.
While usability, HCI, UX, design thinking, and so on, are used in the world of tech startups, other concepts of CSE like JCS and the HSI iterative cycle of systems engineering have not made their way there yet. Therefore, I will use my knowledge of these methodologies and related processes and tools to help startups with user and customer research, and improving their products with that knowledge–iteratively throughout their product lifecycles.
Problem-Solution Fit
To help startups perform user research to achieve problem-solution fit, I will study users’ and customers’ problems and their environments that are relevant to the envisioned product. Including their environments is necessary because their problems do not exist in a vacuum: they exist because of other factors or constraints in their job or life, and cannot be addressed without addressing those factors, too. Since people’s activities in their lives may or may not fit a consistent schema, I will start by creating empathy maps on potential users and customers. These will involve what they say, think, do, and feel, and possibly what they see and hear.
Then, as I learn more about them, I will add structure to the empathy maps. While a common formalization of empathy maps is personas, which are fictional people that have the attributes documented in empathy maps, I will take inspiration from cognitive work analysis (CWA) when it is possible. CWA maps a worker’s tasks and activities to the goals that they help achieve and the worker’s overall objectives that they are trying to fulfill. CWAs are a powerful CSE tool because they capture a worker’s job in its current state, which help identify inefficiencies that can be addressed with a product, and they can be extended with features of a product to test its success. They can also be combined with personal details to create personas.
Also, although CWA is taken from work-centered CSE research, it can be applied to consumers–i.e., people using a startup’s product outside the context of work. In these cases, overall goals may be social connections, self-worth, or similar ideas, and goals and activities may involve going out with friends or posting on social media, for example.
To enumerate empathy map metrics, potential users can be interviewed and they can be observed doing their job using their existing tools. Together, these methods will identify their job’s overall objectives, the goals to achieve these objectives, and the activities used to achieve these goals. Job observation will then identify the specific tasks taken during these activities and the tools and constraints that affects their execution of tasks. Finally, surveys or focus groups can then be used to discover if these metrics are common among a larger set of potential users.
Once these metrics are discovered, they can be measured, and then bottlenecks or other problems can be identified. These are the opportunities for a new product. To evaluate the empathy map metrics, specific measures must be identified and job observation is needed to record the values of the measures. Similar to empathy map metric enumeration, surveys or focus groups can then be used to discover if these bottlenecks or other problems are common among a larger set of potential users or customers.
Finally, solution improvements can be made to improve these metrics, and the cycle repeats.
Product-Market Fit
To help startups perform user and customer research to achieve product-market fit, I will study previously-identified user’s workflows and customers’ needs. Empathy maps and CWAs may identify some tasks that are part of a user’s activities, but it is not focused on the structure of these activities and tasks. Therefore, I will start by creating user journeys, which are diagrams of the tasks or steps a user goes through while using the product.
Then, as I learn more about them, I will add more details to the user journeys by taking inspiration from cognitive task analysis (CTA). CTAs map tasks and activities to their cognitive states (e.g., goals that the user is trying to achieve with them). Although CTAs are taken from work-centered, CSE research, they can be applied to consumers–i.e., people using a startup’s product outside the context of work–in that, like CWAs above, the goals that the activities and tasks help achieve may be social or personal goals.
For highly structured jobs, and easily-observable tool usage, job observation can be used by itself. For more unstructured jobs, or for tasks that are more difficult to observe, methods like card sorting can be used, where a potential user sorts labeled cards about information, tools, or tasks they can perform to determine the order they prefer to achieve a goal identified in the CWA.
Then, go-to-market strategies and metrics to evaluate them should be identified. In the case of users being the customers, or users being the product to the customers (e.g., attention and data for advertisers), marketing funnels for the identified delivery channels can be extended, or supplemented, with product usage funnels from journeys that are modified with features of a startup’s product. Then, these funnels can be evaluated with analytics events embedded in the product, and user journeys can be evaluated with those analytics.
The customers’ needs also need to be understood, regardless of whether or not they are the same as the user. As a start, customers can be interviewed and documented with empathy maps. Then, workers’ objectives that were identified in the empathy maps can be mapped to their managers’ goals. Also, similar to user journeys, customer journeys can also be evaluated with job observation, interviews, card sorting, or analytics, along four stages (AIDA):
- Their Attention to or Awareness of a product category or the product itself is increased: Advertisements, created content, etc., can be tracked in terms of the number of views they get and the percentage of interactions they get (e.g., click-through, CTR, of ads).
- Their Interest in the product is increased: Starting with the percentage of interactions, other activities related to ads or content can be measured and combined to score how much a lead is interested in the product.
- Their Desire of the product is expressed: Similar to interest, desire can be measured by more direct activity like downloading a product (if applicable), signing up to get notified when it launches, and so on.
- They take one or more Actions: For example, shopping around the product category, trying out the product, or buying the product. Having a certain number of large/popular companies as customers is often used to measure pm-fit, but startups can go further. Measuring product-market fit, both to optimize internally at the startup or for future investors can be done by doing cohort analysis on the metrics mentioned above — i.e., what percentage of people from a previous stage go to the next stage, all the way to buying the product. On the way to reaching product-market fit, a startup should make product improvements to improve these customer and user metrics.
Growth
To help startups grow, I will assist with the use of analytics to help iterate on product features to optimize key metrics–a process often called growth hacking. Analytics will be used for two purposes: to identify differences in users’ or customers’ patterns with a product versus the modified, envisioned journeys mentioned above, and bottlenecks in funnels with the end stages resulting in money for the startup. A common approach to grouping these metrics is “the pirate metrics”: acquisition, activation, retention, referral, and revenue (AARRR, like pirates say).
Existing analytics solutions can be used (e.g., Mixpanel, Heap, Segment), or a custom analytics solution can be created. Then, funnel events need to be inserted into the product to fire off when users take certain actions. Finally, the funnels should be visualized with aggregated data across users.
If the users’ or customers’ patterns do not match the envisioned journeys, then interviews can be done to identify reasons for the differences. Similarly, interviews can be done to identify reasons for bottlenecks in funnels that *do* match the journeys, but do not complete them. Then surveys and focus groups can be used to determine if these reasons are common.
Finally, changes to the product can be made to improve the analytics, and the cycle repeats.