Problem Space
These days, a new cultural dynamic has emerged between job candidates and recruiters. During the COVID-19 pandemic, many candidates took part in the Great Resignation and quit their jobs to find something better, and, as the pandemic issues reduced over time, candidates started making more demands like working remotely and an improvement in company culture. However, as the pandemic lessened, recruiters have started making more demands, too, like requiring employees to come back to the office. As a result, the candidate-recruiter dynamic of making offers and counteroffers has returned and has taken the form of both sides again having high-but-competing hiring expectations.
Both job candidates and recruiters are still struggling with connecting with one another, too. On one hand, both are overloaded with the number of job opportunities and candidates on the internet, and, on the other hand, both struggle with finding the right job opportunities and candidates. The latter issue is partly because the right fit might not be even posted on the internet, and, if it is, there are limitations in reaching it. For candidates, this takes the form of applicant tracking systems (ATSs) that automatically scan their resume for specific keywords that aren’t necessarily even on the job listing. For recruiters, this takes the form of having to screen and filter through hundreds of applications for a job and trying to control their conscious and unconscious biases when doing so, such as choosing a candidate based on a specific past employer or their name. Therefore, both parties need improved searching and filtering capabilities.
Throughout the past five years, job candidates have tried many ways and converged to their favored ways to look for jobs, either through personal connections if they are so fortunate, specific online communities, or even search engines. Regardless of their method, they still struggle with a lack of feedback on their applications. Similarly, almost all recruiters are doing hiring online now, so they already have chosen tools like ATSs, but they keep struggling with data management and ensuring their compliance with regulations while trying to ensure a good experience for candidates. For both parties, these issues arise due to the time-consuming application process and can be made even worse by technological glitches during the process. Therefore, they both have the need to make the hiring process go more smoothly. Furthermore, both have needs for added security. Candidates cannot easily present their credentials or verify job listings, and they may have concerns about sharing information online, and recruiters cannot easily check a candidate’s references, and both may struggle with language barriers. Therefore, candidates and recruiters need an efficient and secure way to exchange information during the hiring process.
Technical Requirements
Because both job candidates and recruiters again have high-but-competing hiring expectations, there needs to be a way for both of them to explicitly outline these expectations. The current approach to this involves phone calls and zoom meetings, but these are not recorded, and, even if they were, they would have to be processed manually—or, if by automation or crowdsourced to people in a third world country, the transcription would still need to be fixed manually. Therefore, these interactions should be based on text. For candidates’ requirements, this means including it on or adjacent to their resume, and for recruiters’ requirements, it means including them in job listings. Then, candidates will need the ability to tag their resume with job listing requirements before or when applying to the job, and recruiters will need the ability to answer to candidate requirements and save the answers for the business’s records. Therefore, a solution is needed to enable taggable and savable requirements document interactions.
Even though job candidates and recruiters also need improved searching and filtering capabilities, most modern search systems are based on keywords or n-grams (a series of keywords in the same order). Instead, also search for synonyms and frequently-used-together keywords—fuzzy searching—is needed. Similarly, fuzzy filtering based on candidate-job listing fitness is also needed instead of direct keyword matching. Because the previous component will make job listings and resumes use tags, searching and filtering will not need to create new tags. However, results of the searching and filtering will need to be savable for future reference and sharing with others. Together, that means a solution is needed to enable fuzzy tag search and fitness filtering with savable results.
To help job candidates and recruiters use an efficient and secure way to exchange information during the hiring process, existing chat tools need to be enhanced significantly. First, most are not secured end-to-end largely because some third party in the process wants access to the data, and this is a data security requirement for both candidates (for their sensitive portfolio materials) and recruiters (for their business data). Second, existing chat systems do not enable saving information once you get it from the other party. They do usually support copying text and pasting it elsewhere, but this is a very manual process that does not necessarily capture the information in its desired. Therefore, such a system must enable tagging information entities by the sender and saving this information to third-party systems. Together, a solution is needed to enable taggable and savable E2E-encrypted chat.
Our Solution
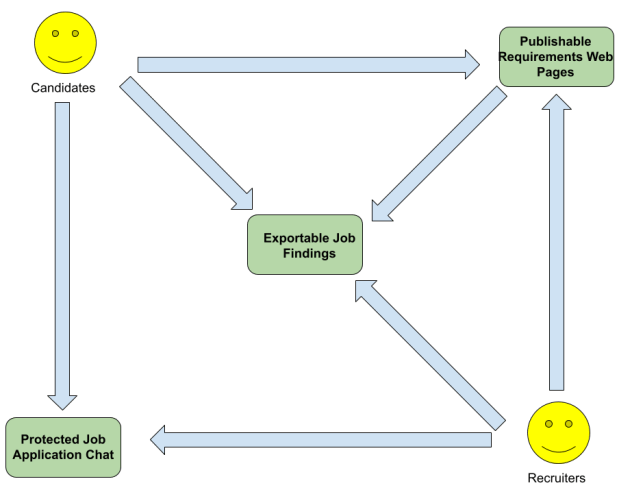
For our solution to enable taggable and savable requirements document interactions, how to tag and save the documents need to be decided. To tag the documents, having the creator highlight text and choose to tag it seems the most straightforward. However, how to save the tags locally and how to present them to the other party are not straightforward. Ultimately, our solution will save them in a database, but this database will not be publicly available. So, we will use a markup language as a solution to saving them locally, transferring them, and rendering them locally by the other party. That enables copying text that contains tags and using them elsewhere if desired.
For candidates, these documents will be surveys for recruiters to fill out to see if they can satisfy the candidate’s requirements, along with their resume. When recruiters supply answers, they will be stored in our solution for the candidate to list and compare multiple job opportunities, and both will be stored in our solution for the recruiter and can be sent to ATSs to track applications to this job.
For recruiters, these documents will be job listings for candidates’ resumes to match the job requirements. They will be saved in our solution and exportable to other job boards. When applying, candidates can rearrange their resume sections and add tags from the job listing requirements. Then, the resumes will be stored in our solution for candidates to reuse and also to export to PDF to apply to jobs outside of our solution, and again in our solution for recruiters and to be exportable to ATSs.
The resulting components will be called Publishable Requirements Web Pages with the same text tagging, saving, and exporting features features, and the ability for creators to start with drafts and publish them when desired. These will be accomplished with making them high-quality HTML documents, partly for the public search feature mentioned below. Also, both will have user- or organization-editable standards to show in the UIs so certain standards will not be forgotten. For candidates, these standards might include best practices in their domain, and for recruiters this might be business standards or metrics, and the fact that keywords used by your ATS should be included in the job listing. On this standards display, eventually some technological automation will also be added to suggest requirements from the users’ past documents and perhaps other public documents on the web.
For our solution to enable fuzzy tag search and fitness filtering with savable results, how we implement fuzzy search and filtering, as well as saving, need to be determined. For fuzzy search, we will start with using Google’s tool (https://programmablesearchengine.google.com/about/) that lets you put their search engine on your website. This means that the resumes with surveys, and the job listings, will be searched on the public web, which is acceptable because they have been explicitly published by their authors. Filtering search results is a different matter because those search results will be updated by incrementally-changed filters, and they are private to the searcher. Therefore, we will use one of the many fuzzy matching libraries based on the results from the Google search. For recruiters, we will use the job listing requirements as possible filters, thus making the filtering based on candidate-job listing fitness and acting as a sort of standards that the recruiter should use to filter on. For candidates, we will save filters they used from other job opportunities so they can be listed and compared to each other to decide on which ones they prefer. For saving, search queries and filters wille be saved in our solution, of course, making the searches a sort of draft being saved by the user. Then, the search and filter results will also be exportable to external systems. The resulting component will be Exportable Job Findings.
For our solution to enable taggable and savable E2E-encrypted chat, the tagging and saving will use similar or the same code as our other components. Specifically, survey answers and job applications will be stored in the E2E chat and thus not be publicly searchable, but will be copy-and-pasteable, and the tags will be saved to our solution and exportable to external sources. Like the components above, standards will be listed adjacent to the chat to remind users about business metrics, government compliance, and professional manners, which for this third component will also include reminding recruiters to give feedback to candidates after they have evaluated their applications. Eventually, automation may be added to use the saved chat tags to evaluate the success of the job listing for the recruiter and the success of a resume for the candidate across job listings.
The E2E chat will be provided by the Signal messaging application because it is the world’s best chat platform that is, it is open source, and it always will be E2E encrypted. It is also created and maintained by the Signal Foundation, a non-profit with the mission to “protect free expression and enable secure global communication through open source privacy technology.” Together, this solution component will be called Protected Job Application Chat.