Problem Space
As the world becomes more connected and more complex, it is increasingly difficult to know what to believe: events happen far away from us, to other people, and we usually hear about them after the fact. A long time ago, we would get this information from newspapers. More recently, there were also television stations that focused on local news.
Nowadays, there are so many online sources of information — from newspaper websites to social media posts — that it overloads us and makes it difficult for us to discern what information is important. As a result, many people have started completely ignoring the news. For media literacy in our democracy, those people should still be kept aware of important news. Therefore, we need a new way to get the news that is important to us.
It is also difficult to know which information sources are reliable. Unreliable sources frequently publish fake news and unverified information that serves political or ideological agendas. As a result, echo chambers and filter bubbles are created that limit exposure to diverse perspectives. This is also very destructive to our democracy. Therefore, we need a new way to determine what news sources are reliable.
Even if a new source is otherwise reliable, they often have pressure to publish quickly, attract clicks, and make more money. As a result, there is less thorough fact-checking and investigative reporting, as well as less context and background information. Even quality news articles are often framed with clickbait headlines and sensationalist content, and are often hidden behind subscription paywalls — even articles that are essential information for our democracy! Therefore, we need a new way to obtain the content and context hidden in articles from reliable news sources.
Technical Requirements
To help people get the news that is important to us, different people’s conceptions of importance and usage contexts throughout the day need to be supported. For different conceptions of importance, the author can communicate the importance to their followers in a way that they understand it due to their personal connection to the author, or, failing that, in a way that most people in their social groups would probably understand. For different usage contexts throughout the day, a technology can be designed to “fit” into a user’s life with different mediums or platforms they can choose to use at different times of the day. Therefore, a solution is needed to enable social communication of important news throughout the day onto multiple platforms.
To help people determine what news sources are reliable, critically thinking about sources’ reliability is very taxing, so it should be assisted somehow with crowdsourcing from multiple people or with technological automation. A source can be said to be more reliable if it publishes more true articles. Automation is good at counting things, and crowdsourcing counting seems unnecessary, but judging an article to be true is ultimately a contextual judgment, therefore must be done by humans. Therefore, a solution needs to provide ways for one or more users to decide if it’s true, and can be enhanced with information that suggests the truth of of an article and the reliability of the source. Therefore, a solution is needed to provide information about source reliability and article truth adjacent to a way for users to decide if an article is true.
To help people obtain the content and context hidden in articles from reliable news sources, the the articles need to be summarized and the headlines need to be represent the content of the article. Summarizing news articles can be done manually, but that would mean creating summaries could not be done quickly and easily. To extend the efficiency of creating summaries, it can be assisted by crowdsourcing to other people or automation. Because the content that readers need to broadly understand the article is a human judgment, automated or crowdsourced assistance can be used to suggest content, rather than forcing the author to copy content from the article themselves, but the author still needs to make the final call. Similarly, assistance can mark a headline as likely clickbait and can suggest another headline, but, again, the human author needs to make the final call. Therefore, a solution is needed to assist authors summarizing articles and improving headlines.
Our Solution
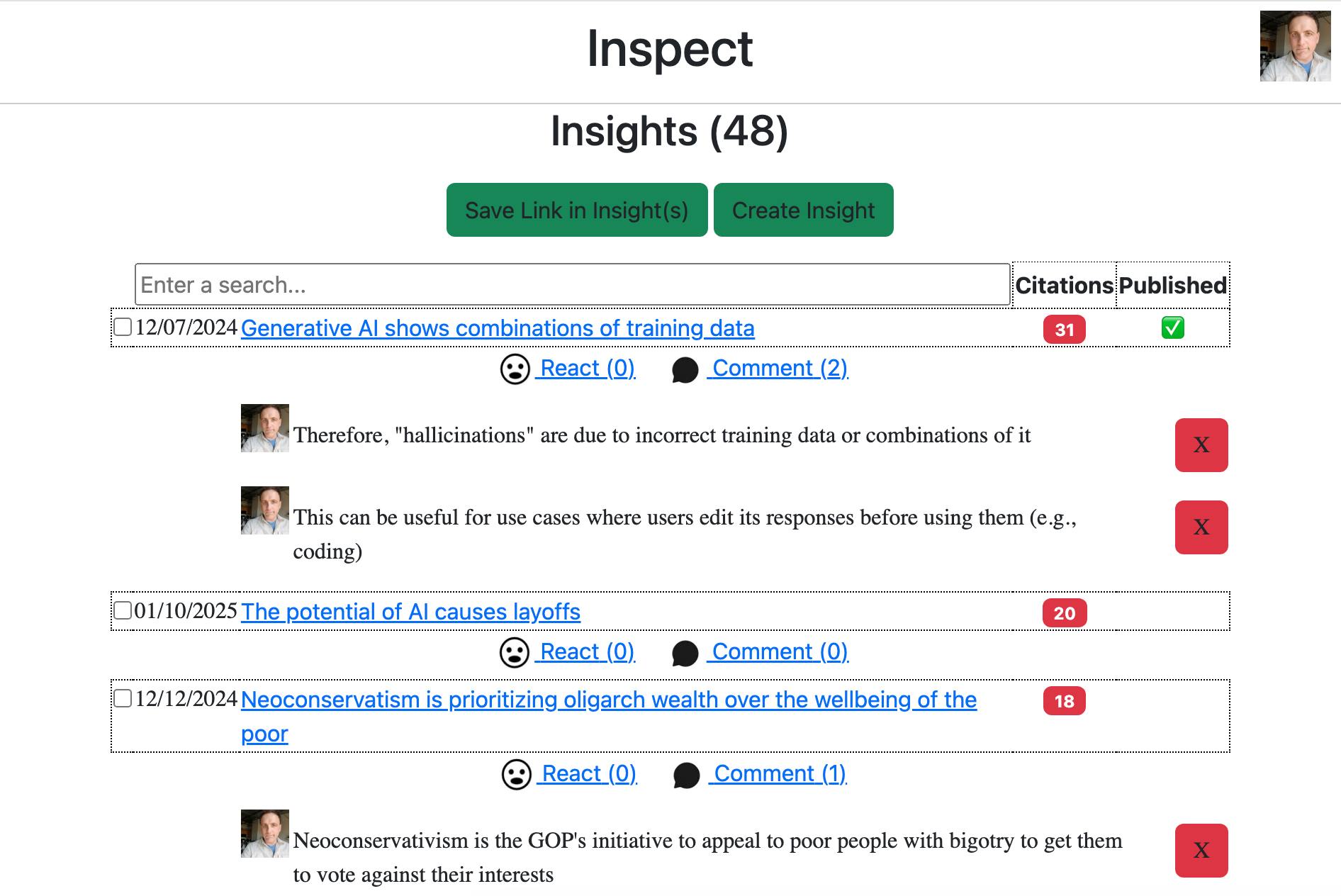
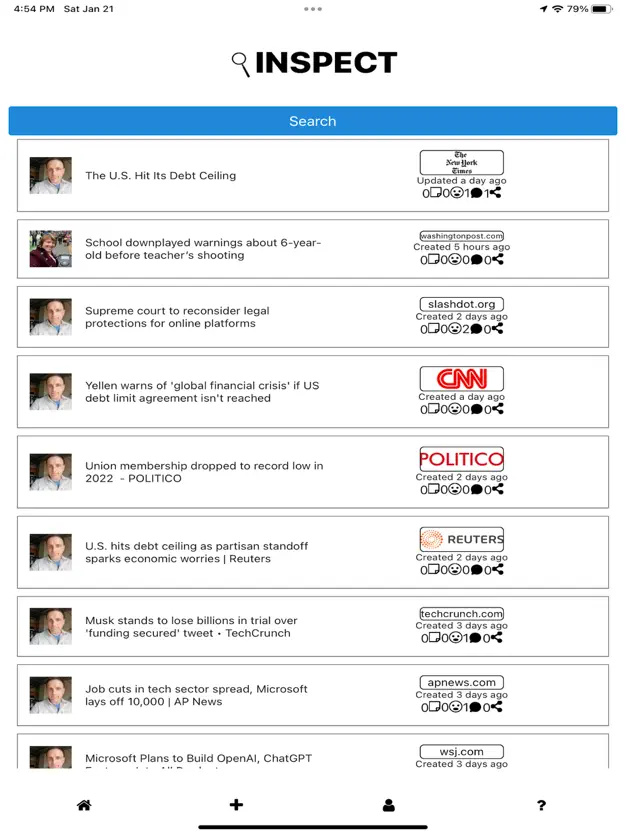
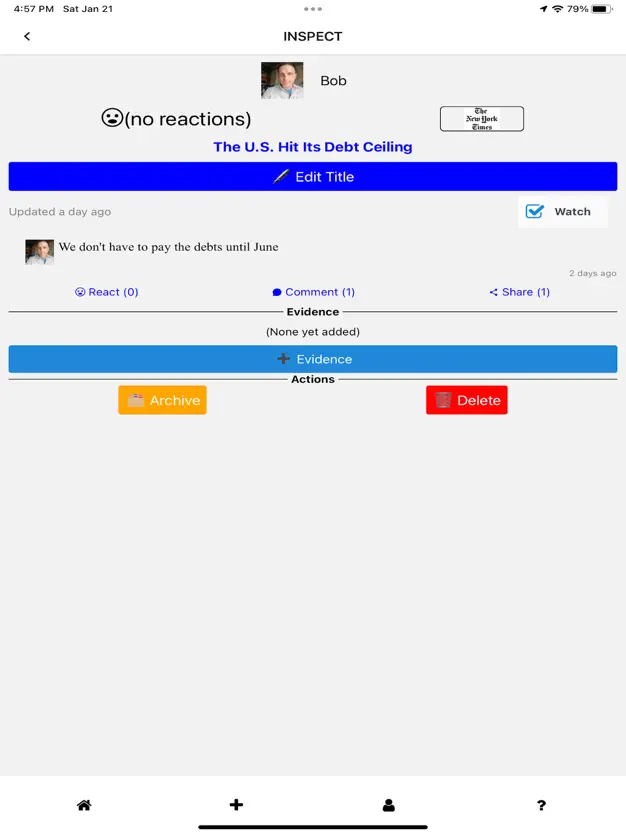
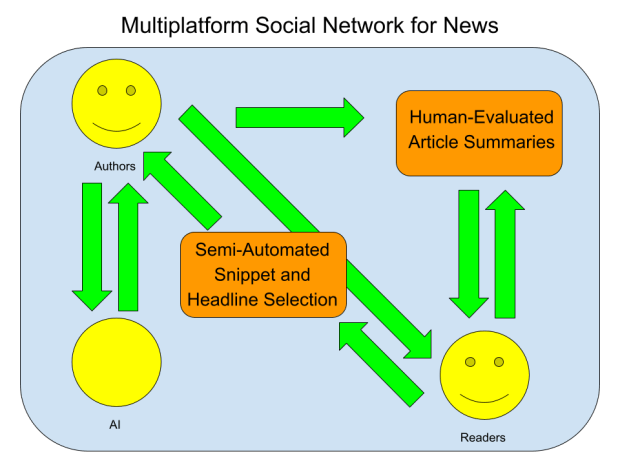
For our solution to enable social communication of important news throughout the day onto multiple platforms, the types of social communication and the various times and platforms that are supported need to be determined. Nowadays, social communication online is often done with text and emojis, and emojis are now included in unicode text. What is not included in unicode text is images. Therefore, our solution will support communicating news summaries with unicode text and images. For multiple platforms and usage over time, our solution will include: a mobile app for both iOS and Android, web pages representing summaries, email digests, and easy sharing to all social media platforms. We will combine these ideas into a Multiplatform Social Network for News that will start out as the mobile app being used to create summaries and share their web pages on social media, and will hopefully turn into people signing up for Inspect to get email digests, and eventually to download the mobile app, where they will get more immediate notifications of new summaries and create their own summaries.
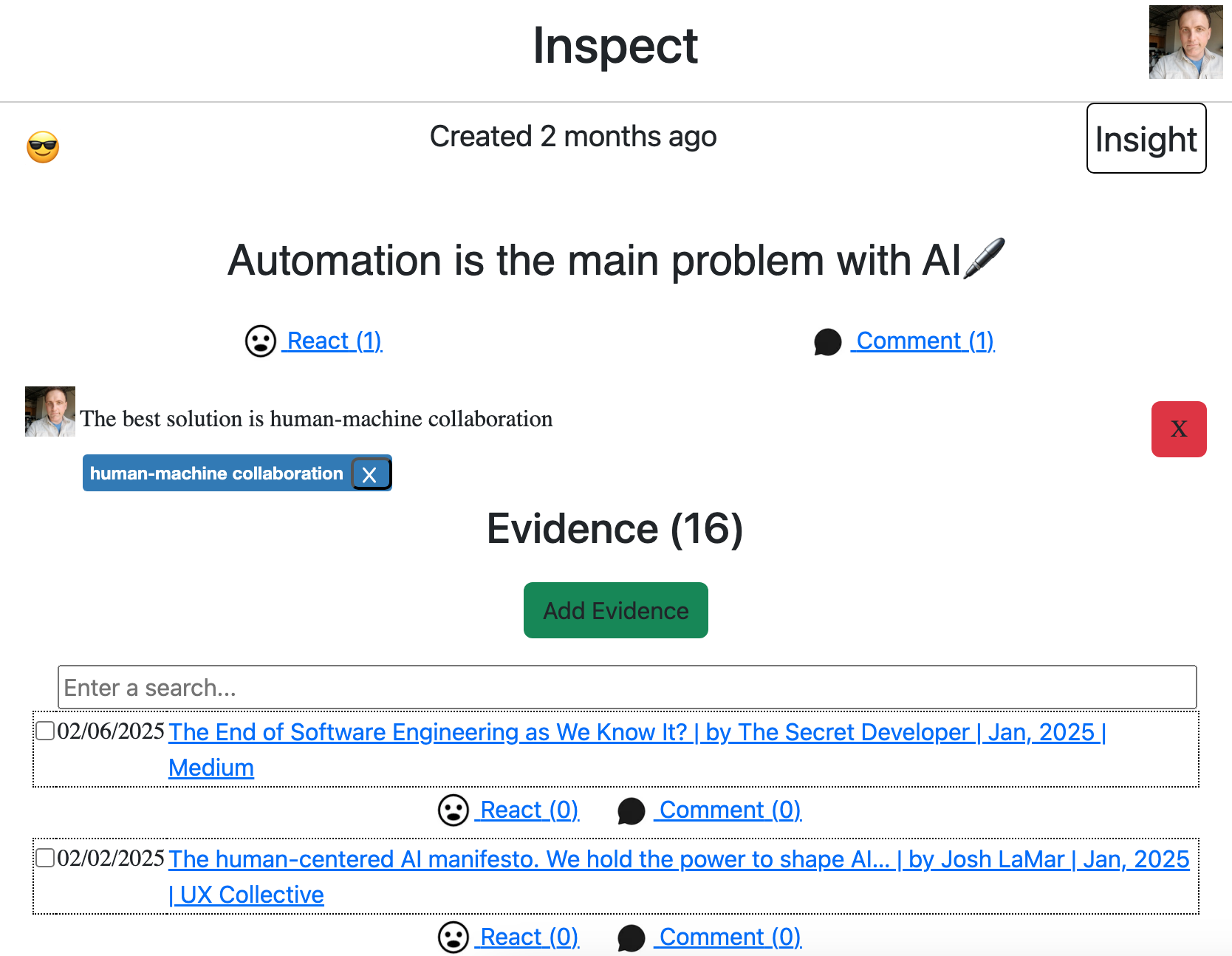
For our solution to provide information about source reliability and article truth adjacent to a way for users to decide if an article is true, our solution will use a combination of the human author and crowdsourcing other users. The first component to communicate source reliability and article truth will be snippets taken from the article. These are discussed more in the next paragraph, but for source reliability and article truth, they can communicate the rationale behind the article and any sources that it cites. Not only are the snippets helpful for people who don’t have subscriptions to the news source, they also help avoid legal issues from the news source for plagiarizing their entire articles. Then, when other users see these snippets and understand what the article is about, they can discuss among themselves whether or not they think the article is true. Our solution will use discussion threading like other popular social media platforms do, where users can reply to one another and easily see the discussion history. As they become more confident that they know whether or not the article is true, they will be able to vote on it, and the truth value of the article summary will be whether true or false have more votes. Finally, the news source’s reliability will be recalculated based on how many true articles it has published and have been summarized on Inspect, and it will be visualized with common meta-information methods like color (e.g., red – yellow – green) or opacity. The resulting summaries will be called Human-Evaluated Article Summaries.
For our solution to assist authors summarizing articles and improving headlines, we will again use article summaries with snippets, but in this paragraph we will discuss how authors can be assisted by crowdsourcing other users and eventually some technological automation. As implied above, the author can insert the snippets, but we will make it so that other users can suggest snippets to the author, too and, eventually, an automated algorithm will also be available to suggest snippets by intelligently parsing the articles. Similarly, other users can mark the headlines as clickbait, notifying the author that they should change it, and also suggest new headlines that are more informative. Eventually, automation will also be able to mark headlines as clickbait and suggest new headlines that are more informative. The resulting component will be called Semi-Automated Snippet and Headline Selection.